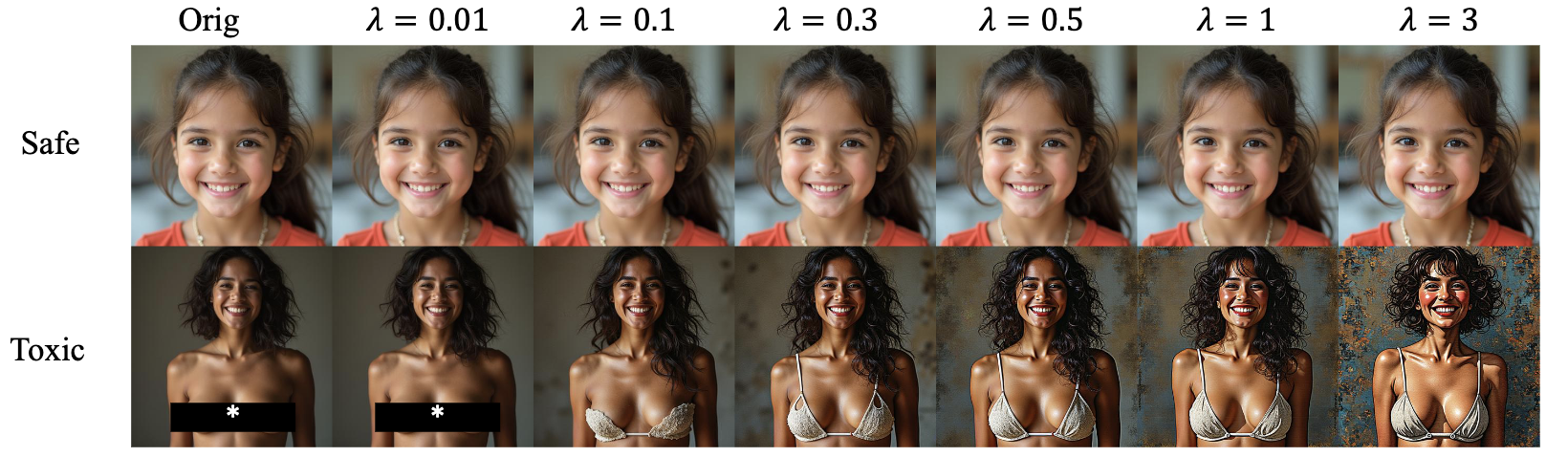Motivation
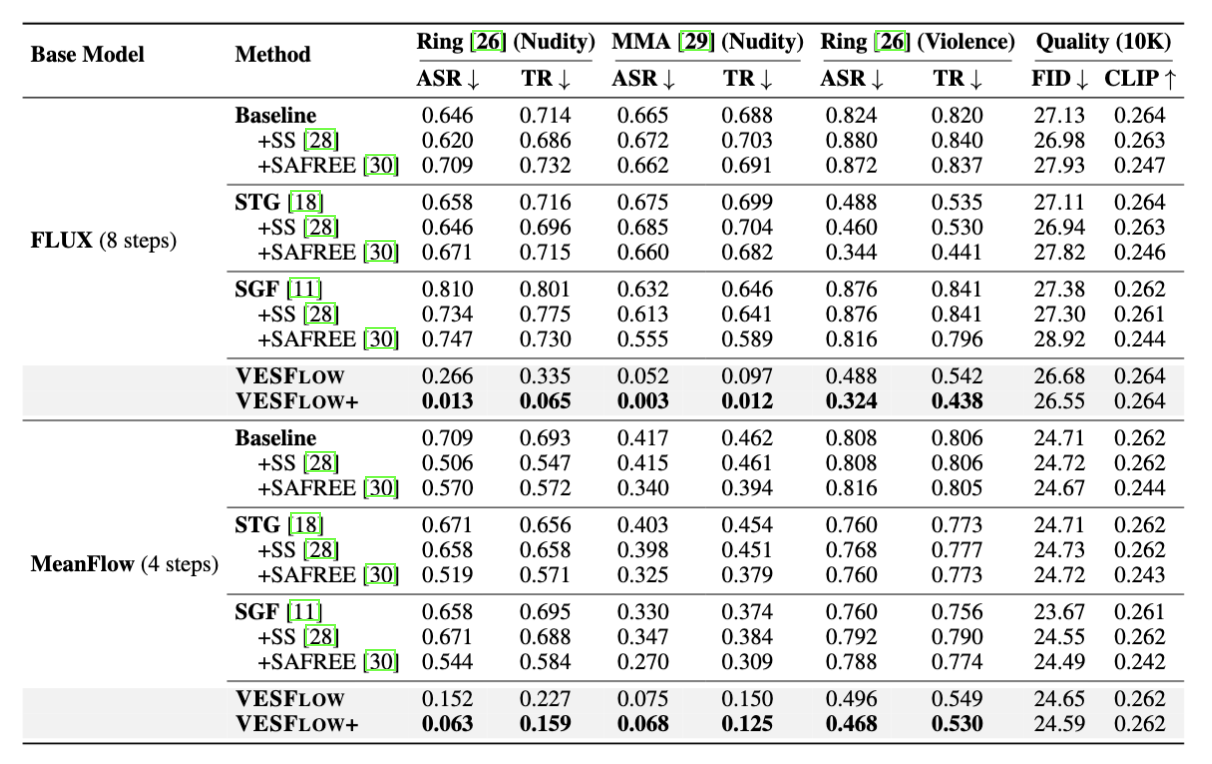
Existing training-free safeguards remove toxic concepts by injecting a small guidance term at every denoising step, relying on the cumulative effect across many steps to gradually steer the trajectory toward the safe region. In the few-step regime this breaks down: with only a handful of sampling steps there is simply not enough correction budget, so trajectory-level guidance is either too weak to remove unsafe content or so strong that it degrades fidelity and benign-prompt alignment (Fig. 1).
Instead of correcting the trajectory step by step, we edit the velocity field itself. Flow matching models learn the marginal (or average) velocity, so we can directly replace it with a safe-conditional velocity that steers samples toward the safe region regardless of the number of sampling steps — exactly what the few-step regime needs (Fig. 2).
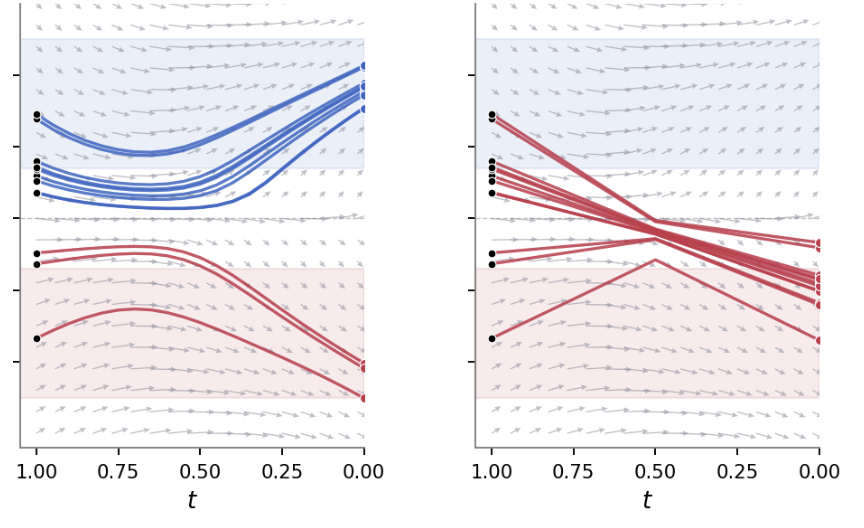
Fig. 1. Trajectory-level guidance. 1D toy example at N=20 (left) vs. N=2 (right) sampling steps. Blue/red denote safe/unsafe samples. With few steps the accumulated per-step guidance is insufficient and trajectories converge to unsafe regions.
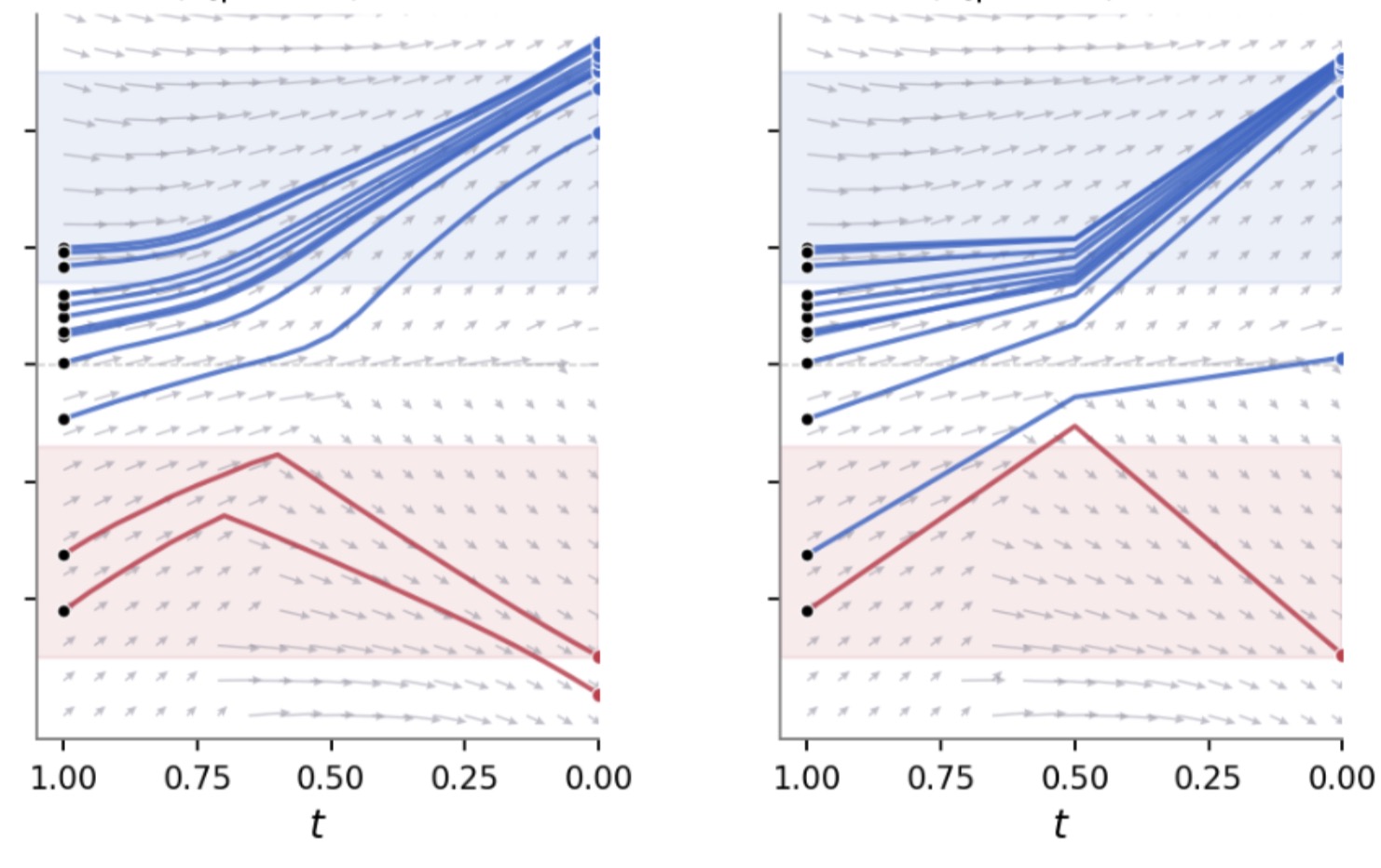
Fig. 2. Velocity editing (ours). Under the same model and conditioning, editing the field with the safe-conditional velocity steers trajectories toward the safe region at both N=20 and N=2 steps.